
| 資訊處理流程 | 生成 | 收集 | 儲存 | 使用 |
|---|---|---|---|---|
| Thanos | ✓ | ✓ |
到了 Prometheus Long Term Storage 議題的最後一篇,登場的是拯救宇宙生態浩劫後解甲歸田當農夫的 Thanos。

圖片來源:Pinterest
Thanos 最初是由 Improbable 為應對內部大量 Infra 與服務的 Prometheus Metrics 監控需求,而開發的內部專案。該專案於 2017 年 11 月開源,並在 2019 年加入 CNCF,現為 CNCF 的 Incubating Project。Thanos 主要有四個目標:
根據 Improbable 官網,該公司自我定位為「Metaverse Technology Company」,創立於 2012 年。其主要產品是 SpatialOS,一個用於開發大型多人遊戲的開發平台。遊戲開發者僅需將遊戲部署在 SpatialOS 上,就能讓遊戲支援多人遊玩,無需自行維護伺服器、網路連線或資料庫等基礎設施。因此,Improbable 不僅是遊戲平台提供者,也是大型雲端服務提供者,這讓他們在監控與資料儲存的需求相當大,這也是 Thanos 誕生的背景。
Thanos 的架構如下圖所示,分有 Sidecar 和 Receive 兩種模式:
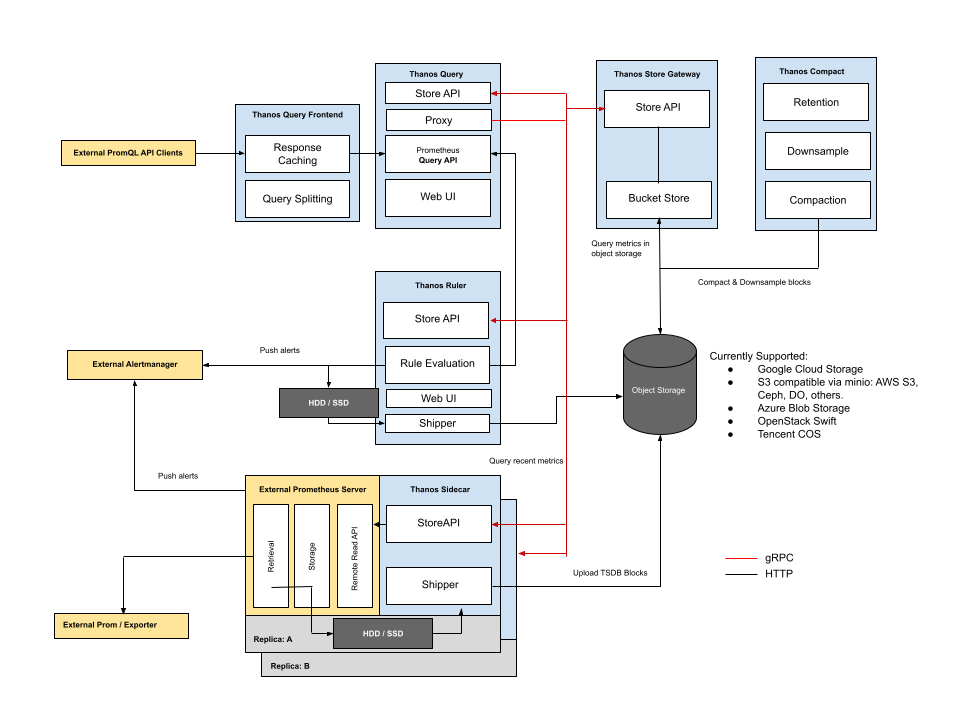
Sidecar 模式,Sidecar 負責對 Prometheus 爬取 Metrics。圖片來源:thanos.io
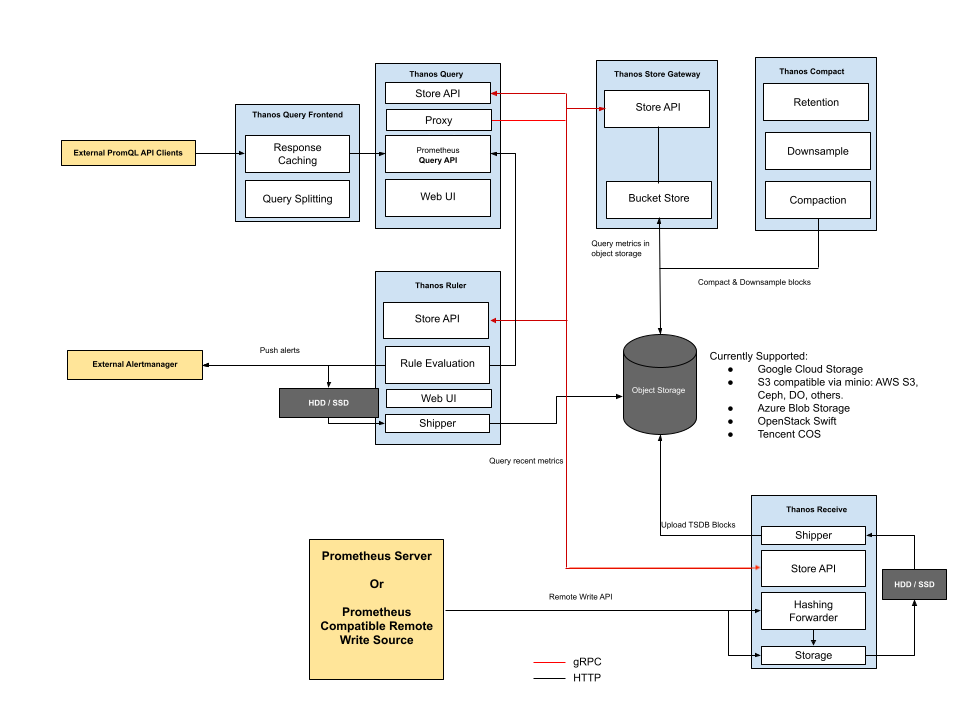
Receive 模式,Receiver 接收 Prometheus Remote Write 的 Metrics。圖片來源:thanos.io
各元件的功能如下:
在使用 Sidecar 模式時,配對的 Prometheus 必須將 --storage.tsdb.min-block-duration 和 --storage.tsdb.max-block-duration 兩個參數設定為相同的值。透過這樣的設定,Prometheus 的 Compaction 功能會被關閉,讓 Thanos Compactor 能夠正常運作。如果設定不一致,Sidecar 啟動時會報錯。建議兩個參數的值設定為 2h,而 Lab 中使用的 5m 設定僅為驗證 Sidecar 能正常將資料上傳到 Object Storage。相關細節說明可參考 Sidecar Component 的文件。
在介紹過 Cortex 與 Mimir 之後,這次終於看到一個不同的主打功能:Downsampling,這也是 Cortex 與 Mimir 目前所缺少的。一般來說,Prometheus Metrics 的採樣頻率可能每 15 秒就有一次。但是,當進行長時間範圍的查詢時,Prometheus 並不會回傳該時間範圍內的所有數據。實際上,它會根據 Range queries 中的 Step 參數,來決定回傳多少數據。以一年的時間來說,單一個 Series 就會有 210 萬個數據點。對使用者來說,一次取得這麼多的資料不僅難以視覺化,也沒有太大的實用性。
雖然 Prometheus 可以透過 Step 參數減少回傳數據量,但這樣取得的單點數據未必能代表鄰近的數據點。更何況,這樣還需花費更多時間來處理和選擇要回傳哪些數據。舉例來說,把一年的數據量縮減到一週一個數據點,共 52 個,這 52 個數據點只能代表取樣時的那個時間點,而非整週的數據。因此,透過預先進行降取樣,並透過計算方式將一週的所有數據歸納為一個數據點,可以取得更有代表性的數據。這樣同時也能降低查詢時間,因為不必再花費時間處理和選擇要回傳的數據,而是直接獲得預先計算好的數據。
有人可能會認為,Downsampling 除了能加速查詢之外,也會減少儲存空間的需求。但實際上情況並非如此。在 Thanos 的設計裡,即使進行了 Downsampling,也不會移除原始的資料,反而會增加儲存空間的使用量。保留原始資料的好處在於,如果在長時間的查詢結果中發現異常,仍然可以透過原始數據進行更細致的分析。這個常見的錯誤認知,Thanos 的文件也有特別指出:
Keep in mind that the initial goal of downsampling is not saving disk or object storage space. In fact, downsampling doesn’t save you any space but instead, it adds 2 more blocks for each raw block which are only slightly smaller or relatively similar size to raw blocks.
範例程式碼:10-thanos
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
關閉所有服務
docker-compose down
啟動所有服務
docker-compose -f docker-compose.receive.yaml up -d
檢視服務
admin/admin
關閉所有服務
docker-compose -f docker-compose.receive.yaml down
總結而言,Thanos 是一個專為解決 Prometheus 長期儲存和查詢需求而誕生的開源專案。除了提供資料的長期儲存、多來源整合和查詢加速,特別加入了降取樣功能,讓使用者能更有效地進行長期和大規模的數據分析。這一切也得到了社群的廣泛支持,包括 Red Hat 的工程師積極參與其開發。例如,Red Hat 的 OKD 和 OpenShift 預設的 Monitoring Stack 便融入了 Thanos 的部分組件。這種大量採用可能也與在 Improbable 創建 Thanos 的 Bartek Plotka 曾轉任至 Red Hat 有密切關係。
至此,Prometheus 的三個長期儲存工具 Cortex、Mimir 和 Thanos 都已經介紹完畢。選擇哪一個工具,最終還是回到最初的問題:「你的需求是什麼?」只有最適合的,沒有最好的。不過,在觀察這些工具的發展歷程時,會發現才華洋溢的工程師總會帶著他們珍貴的經驗轉任到不同的公司。例如,Cortex 的最初開發者 Tom Wilkie 將經驗帶到了 Grafana Labs,並進而發展出了新的 Mimir;而 Thanos 的開發者 Bartek Plotka 也是如此,將經驗帶到 Red Hat,而現在則轉任至 Google,擔任 Google Managed Prometheus 的 TechLead。在未來,也許還有機會在 Google Managed Prometheus 上看到 Thanos 的影子。或許根據這些大神工程師們的經歷,也能判斷一個工具是否值得信賴以及可應用於哪些實際場景。

